
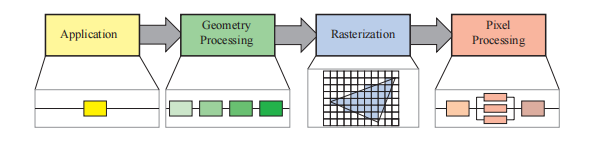
应用阶段
由应用程序进行驱动,在软件中进行实现,大部分时间运行在CPU上,(可以通过计算着色器,让GPU进行计算,比如草地编辑器中,对草的顶点进行计算,以及视锥体裁剪)。最终,需要进行渲染的几何物体会被输入到几何处理阶段
- 碰撞检测
- 全局加速算法
- 动画
- 物理模拟
比如在收到用户输入时,将输入转换为相应的旋转矩阵,然后确保这个旋转矩阵在渲染的过程中会被正确应用
播放相机动画,让相机沿着预定路线进行移动时,从不同的视角来展示这个物体。程序需要根据动画设定,来对相机的相关参数进行更新,位置、视角方向等。应用程序需要将相机位置、光照和模型的图元信息,都发送给管线的下一阶段
几何阶段
负责变换、投影以及其他和几何处理相关的任务。计算哪些物体会被绘制,应该如何进行绘制,以及应该在哪里绘制等问题。运行在硬件处理单元(GPU)上。
变换
模型矩阵到世界矩阵
平移、旋转、缩放操作,缩放需要考虑法线变换(非均匀缩放-逆矩阵的转置矩阵获得变换法线-切线空间)
正确的顺序应该是,缩放、旋转、平移。理解缩放,旋转,平移 - NoBodyNoOne的文章 - 知乎世界矩阵到摄像机矩阵
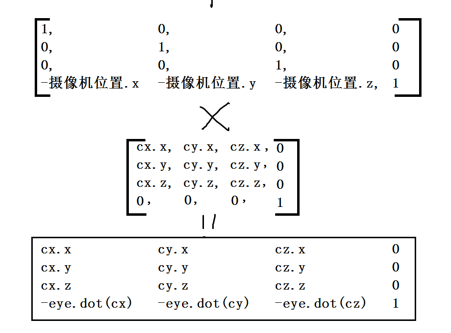
相机参数
EyePosition:摄像机位置
FocusPosition:观察目标点(at)
UpDirection:摄像机上方向(不是Y,相对世界)
Near:近截面、Far:远截面
FOV(vertical field of view):垂直视场角
Aspect Ratio :屏幕纵横比相机变换矩阵计算:
摄像机矩阵到投影矩阵

可以细分为以下几个阶段

- 顶点着色
-
在物体最终进入屏幕的过程中,需要在不同的空间或者坐标系下,进行若干次变换。
可以将若干个模型变换和同一个模型相关联,以便调整自身的位置和朝向。我们可以将若干个模型变换和同一个模型相关联,这样我可以在不复制这个模型的前提下,在一个场景中放置同一个模型的多个副本,每个实例都拥有各自不同的位置和朝向。
-
各个模型经过各自的模型变换之后,所有的模型便位于一个相同的空间中
-
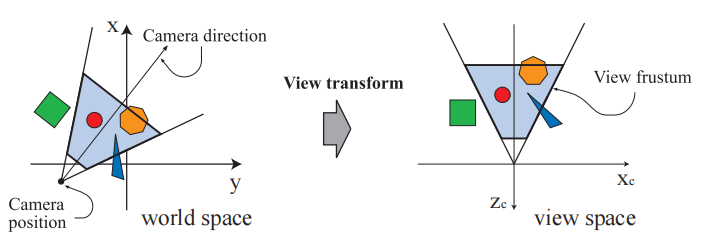
观察变化的目的是将相机放置在原点,并调整相机的朝向,使其看向Z轴负半轴,y指向上方,x指向右方
- 投影
-
分为正交投影和透视投影,在投影变换之后,模型所处的坐标系被称为裁剪坐标系。在坐标除以w之前,都是齐次坐标。
-
GPU的顶点着色器必须始终输出这种类型的坐标,以便于在裁剪阶段可以正常执行
- 可选阶段
- - 曲面细分
- - 几何着色器
- - 流式输出
- 略
- 略
-
可以把GPU作为几何引擎,选择将这些处理好的数据输入到一个缓冲区中,而不是将其直接输入到渲染管线的后续部分并直接输出到屏幕上,这些缓冲区中的数据可以被CPU读回使用,也可以被GPU本身后续步骤使用,通常用于粒子模拟
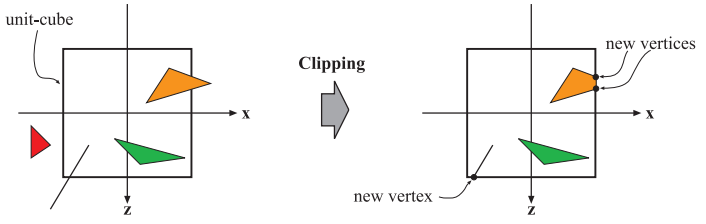
- 裁剪
- 背面剔除
-
完全位于可视空间的图元,将会按照原样传递给下一阶段;完全位于可视空间之外的图元,将不会被传递给下一阶段,对于部分在可视空间内的图元,需要进行额外的裁剪操作,生成新的顶点用来代替可视空间之外的那个顶点。裁剪后,会进行透视除法,把三角形位置转换到三维标准化设备坐标系(NDC)中,(-1,-1,-1)到(1,1,1),几何处理阶段最后一步就是将这个空间转换为窗口坐标系
- 线段裁剪:点面关系,线面关系,通过向量在面上的投影,以及点是否在矩形内;
八方位裁剪法;
- 三角形裁剪:平顶三角和平底三角形,判断出界平移顶点;
- 只跟三角形和摄像机的距离有关,不依赖摄像机朝向;根据三角形顶点顺序,叉乘出法向量;顶点顺时针法向量朝外剔除,逆时针朝内剔除
- 屏幕映射
- 透视剔除
- 视口变换
- 通过执行透视除法获得归一化的NDC坐标,z值在视口变换过程中被映射到[-1,1](OpenGl)、[0,1](DirectX)
- NDC坐标映射到窗口坐标需要通过平移和缩放过程(相机的宽高比),xy为窗口相对于屏幕的位置
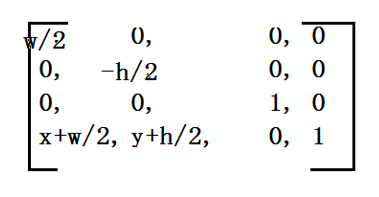
应用阶段会提供投影矩阵(P)给几何处理阶段,对于每个物体,应用程序都会计算一个矩阵(MV),描述观察变换以及物体本身的位置和朝向。物体的顶点和法线会通过这个矩阵变换到观察空间中,经过顶点着色和其他计算后,根据投影矩阵将相机的可视空间变换为一个标准立方体,进行裁剪,获得完全位于标准立方体内部的图元。最后顶点会被映射到屏幕上的窗口中。结果数据会被输入到下一阶段
光栅化阶段
将构建三角形的三个顶点作为输入,找到所有位于三角形内部的像素,并将其转发到下一个阶段。是一个将屏幕空间中二维顶点,转换到屏幕上像素的过程,每个顶点都对应一个z值(深度缓冲)和各种各样的着色信息。都是使用了专门的硬件单元进行执行
找到所有位于图元内部的像素,然后将其发送到管线的像素处理阶段
判断三角形和屏幕上的哪些像素重合,取决于如何实现GPU管线。比如:
1:点采样。最简单的方法就是直接将每个像素的中心点来作为该像素的样本,如果该像素的中心点位于三角形内部的话,则该像素也位于三角形的内部。还可以使用超采样或者多重采样抗锯齿技术,来对每个像素进行多次采样。
2:保守光栅化,即当某个像素只要有一部分与三角形重叠时,就认为该像素位于三角形内部
- 三角形设置
- 三角形的微分、边界方程和其他数据,都会在这个阶段进行计算,这些数据可以用于三角形遍历,以及对几何处理阶段产生的各种着色数据进行插值。一般会使用固定功能的硬件实现
- 三角形遍历
- 对每个被三角形覆盖的像素(中心点或者样本点在三角形内部的像素)进行逐个检查,并生成一个对应的片元。找到那些位于三角形内部的点或者样本,并且会对三角形三个顶点上的属性进行插值,获取每个三角形片元的属性,包括片元的深度,以及几何阶段输出的相关着色数据等。
- 线段的扫描转化
- 数字微分画线算法DDA
- 多边形填充
- 重心计算多边形片元颜色:
像素处理阶段
计算像素的颜色,并执行深度测试,来判断这个像素是否可见。执行一些逐像素的操作,将颜色进行混合等。可以被划分为像素着色和合并两个阶段。
计算每个可见图元所覆盖像素的颜色值。最后生成一副图像,显示在屏幕上。
锯齿和抗锯齿
- 超级采样抗锯齿(SSAA)
- 多重采样抗锯齿(MSAA)
-
将原图分辨率放大一倍,再采样;光栅化和片元着色器开销都是原先四倍,渲染缓冲开销也是四倍
-
每个片元有多个采样点,计算采样点的覆盖率,光栅化阶段计算采样点覆盖率,在片元着色器计算颜色值后乘以这个覆盖率;
-
MSAA和延迟渲染不兼容(延迟渲染需要Geometry和Lighting两个Pass,Lighting阶段无法通过GBuffer获得片元覆盖率)
阴影
- 光照烘培得到Shadowmap;先光照烘培获得深度信息,再通过阴影贴图判断那些片元落在阴影中;Shadowmap的精度会导致阴影粉刺,需要偏移深度来消除粉刺现象;
- 阴影锯齿通过百分比渐进过滤(PCF)实现软化阴影(softshadow)
像素着色
- 使用插值过的着色数据作为输入,进行逐像素的着色计算,生成一个或者多个颜色值。最终会输出每个片元的颜色值,这些颜色值会被输入到下一个子阶段中
合并
- 这个阶段的任务是将颜色缓冲中的颜色组合起来。这个阶段被称为光栅操作管线(ROP)或者渲染输出单元。执行这一阶段的GPU子单元,并不是完全可编程的;但它仍然是高度可配置的,可以支持各种效果
- 可见行问题,当一个图元要被渲染到某个像素上时,会计算这个图元的z值,并将其与z-buffer中对应像素深度进行比较。z-buffer允许图元以任意顺序进行渲染。但不适用于透明物体。透明物体需要在所有不透明物体渲染后,才能进行渲染,并且严格按照从后往前顺序进行渲染,或者使用一个顺序无关的透明算法。较老的api中,会使用透明通道进行透明测试,现在基本在像素着色器中完成
- 模版缓冲,记录被渲染图元的位置信息,每个像素包含8bit。图元可以通过各种各样函数来杯渲染到模版缓冲中,同时模版测试可以用来控制渲染到颜色缓冲和z-buffer中的内容。
- 双缓冲机制
- 场景的渲染都会在屏幕外的后置缓冲区中进行。当场景被渲染到后置缓冲区后,后置缓冲区会与显示在屏幕上的前置缓冲区交换内容。通常发生在垂直回扫的过程中
渲染顺序
- 画家算法
- 顺序无关半透明算法
- 对于不透明物体,先从前往后渲染;不透明物体渲染前先进行深度检测(这里应该值得是执行完片元着色器后,根据深度值进行深度检测,之所以在片元着色器后,应该是考虑半透明物体的透明度剔除处理等操作,可以先通过在片元着色前进行深度检测,但是这类的shader不能有透明度剔除操作,unity中通过DepthOnly pass,提前计算深度),没通过深度检测的物体,不会进行深度写入的操作
-
双向剥离:两个方向剥离,一个从前往后,一个从后往前,两个方向效率更高